


 Download files
Download files Verified to work with the
Verified to work with the  To install the software needed to reproduce this system with the
To install the software needed to reproduce this system with the
 To set up the environment on the UCSF Wynton cluster to run
this system, run:
To set up the environment on the UCSF Wynton cluster to run
this system, run:
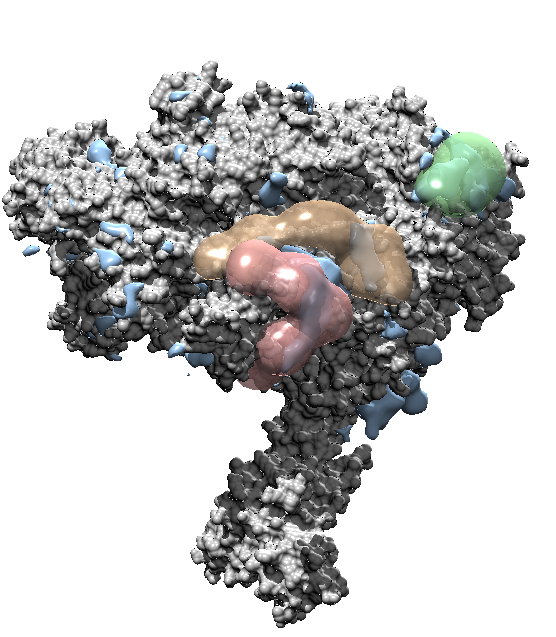
These scripts demonstrate the use of IMP and PMI in the modeling of the Pol II(G) complex using DSS chemical cross-links.
40 DSS cross-links involving gdown1 were identified via mass spectrometry. 14 of these cross-links were intramolecular and 26 were intermolecular with Pol II. The Pol II structure used was obtained from the PDB (code 5FLM); it was determined primarily based on a cryo-EM density map at 3.4 Å resolution (EMDB code: 3218) Bernesky, 2016 Nature.
Representation of gdown1 relied on (i) secondary structure and disordered regions predicted by PSIPRED based on the gdown1 sequence (Buchan et al., 2013; Jones, 1999).
-
sample.py: PMI modeling scripts for running the production simulations: The search for good-scoring models relied on Gibbs sampling, based on the Metropolis Monte Carlo algorithm. We suggest producing at least 5 million models from 100 independent runs, each starting from a different initial conformation of gdown1 to have proper statistics. -
submit.sub: SGE cluster based submission scripts to run automatically 100 independent runs. -
The compressed 100 independent trajectories are accessible at:
/salilab/park3/ganesans/gdown1_trajectories/gdown1.tar.gz
Various scripts to analysis the simulations. We give more details scripts that allows us to test for sampling convergence.
-
select_good_scoring_models.py: Python script that reads and selects RMF files based on good scoring model criteria explained in the methods section. -
random_subsets_best_score_convergence.py: we test if adding more models improves our sampling of top scores. The input to the script is a list of all theTotal_Scorefrom the simulations. For each subset, we perform 100 sub-samplings to compute error bars. We give the file twice to check how the error bars varies. -
Kolmogorov_Smirnov_2Samples.py: we test if the distribution from two independent subsets are not unsimilar. -
The good-scoring models that have been selected for precision-based clustering based on RMSD metric are located in:
results/Models. The file name format is${trajectory_number}_${frame_number}.rmf3 -
sample_precision.py: Given a RMSD matrix (results/Clustering/rmsd_matrix.tar.gz), we compute the 𝛘2-test for homogeneity of proportions{McDonald, 2014} and compute the best precision for which sampling has converged. -
rmsf.py: Given a list of structures, compute the average RMSF, which indicates the precision of the structures in a cluster.
Python scripts for generating figures from the paper.
Author(s): Sai J. Ganesan
Date: September 6th, 2018
License: CC BY-SA 4.0 This work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
Last known good IMP version:
Testable: Yes
Parallelizeable: Yes
Publications: Miki Jishage, Xiaodi Yu, Yi Shi, Sai J. Ganesan, Andrej Sali, Brian T. Chait, Francisco Asturias, and Robert G. Roeder Architecture of Pol II(G) and molecular mechanism of transcription regulation by Gdown1 Nat Struct Mol Biol. (2018) 25(9):859-867. doi: https://doi.org/10.1038/s41594-018-0118-5