


 Download files
Download files Verified to work with the
Verified to work with the  To install the software needed to reproduce this system with the
To install the software needed to reproduce this system with the
 To set up the environment on the UCSF Wynton cluster to run
this system, run:
To set up the environment on the UCSF Wynton cluster to run
this system, run:
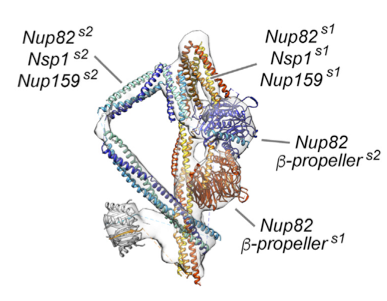
These scripts demonstrate the use of IMP, MODELLER, and PMI in the modeling of the Nup82 complex using DSS/EDC chemical cross-links and electron microscopy (EM) 2D class averages.
First, MODELLER is used to generate initial structures for the individual components in the Nup82 complex. Then, IMP is used to model these components using DSS/EDC crosslinks and the electron microscopy 2D class averages for the entire Nup82 complex.
The modeling protocol will work with a default build of IMP, but for most effective sampling, IMP should be built with MPI so that replica exchange can be used.
-
datacontains all relevant data*.pdb: Representation PDB for individual domains of the Nup82 complex*.csv: Cross-links dataprotein_fasta.*.txt: Sequence filesdata/4ycz_3ewe: Representation PDB for the Nup82 - Nup84 complexesdata/em2d: EM 2D class averages of the Nup82 complexdata/em2d_without_bg: EM 2D class averages of the the Nup82 complex (background removed)data/MODELLER: Comparative model outputs, generated using MODELLER (using templates of 5CWS and 5C3L)
cc_tr1: Nsp1_637_727 + Nup82_522_612 + Nup159_1211_1321 (using 5CWS as templates)
cc_tr2: Nsp1_742_778 + Nup82_625_669 + Nup159_1332_1372 (using 5CWS as templates)
cc_tr3: Nsp1_788_823 + Nup82_678_713 + Nup159_1382_1412 (using 5CWS as templates)
-
EM2D_Filter: contains files for EM 2D filterEM2D_Filter/EM2D-Filter.py: Script to compute a score for a given model against a set of class averages.EM2D_Filter/Get-Distribution-Statistics.sh: Script to analyze the results of the filtering; requires GNUPlot and ImageMagick.EM2D_Filter/Satisfied-Classes-Count.sh: Quick script to format the results of the analysis into a summary text file.EM2D_Filter/Models_Selection_Threshold.py: Script to select models given a threshold (either a user input or a adaptive threshold). -
outputs: contains resulting structures and output filesoutputs\1_prefilter: Selection script of 463 good-scoring models ranked by the combined total score.outputs\2_Sampling_Exhaustiveness_test: "Sampling Exhaustiveness test" resultsoutputs\3_analysis_allEM2D: Clustering analysis results and scriptsoutputs\3_analysis_allEM2D\kmeans_10000_2: Localiazation probability densities and the RMSD distance matrix for 2 clusters (major: cluster.0_370 and minor: cluster.1_93)outputs\4_em2d_single_scores_final35r_best: Validation of the final Nup82 complex structure using the EM 2D class averages. A representative structure ("225-17.rmf3" and "225-17r_n159nter_n116_removed.pdb") selected in the major cluster (cluster.0_370) was used for validation.outputs\5_GFP: Validation of the final Nup82 complex structure using the GFP tags (EM 2D image)outputs\6_Nup82Nup84: Modeling of the Nup82 - Nup84 complexes -
Predictions: Predictions from COILS/PCOILS, DISOPRED, HeliQuest, Multicoil2, and PSIPRED. Also contains template search results using HHPred. -
SAXS: SAXS data and validation of the corresponding Nup82 complex fragments -
templatecontains modeling scripts
1_run_initial_random_EMclass2.sh: script that runs the PMI script 1_modeling_initial_random.py.
2_run_refinement.sh: script that runs the PMI script 2_modeling_allEM_except11_19.py.
- python 1_modeling_initial_random.py -r repeats -out outputdir -em2d class_average -weight em2d_weight
The script will generate independent and uncorrelated trajectories from different random initial configuration restrained by all data and information available for the system (e.g., chemical cross-linking data, excluded volume, structures) and restrained by one EM 2D class average.
First, we use IMP to register models against EM class averages and then select models that satisfy those class averages the best. Here, the filtering is applied to the Nup82 Complex. The filtering protocol will work with a default build of IMP. The scripts require GNUplot and ImageMagick.
- python EM2D-Filter.py input_rmf_file list_of_class_averages angstrom_per_pixel number_of_projections model_resolution image_resolution frame_of_rmf_to_read
Inputs: input_rmf_file: structure to be projected and registered against class averages list_of_class_averages: text file listing the list of class averages. Output: A list of score for the structure against each image (1-cross correlation).
- bash Get-Distribution-Satistics.sh Inputs: List of files containing the scores. This is hard coded in the script here. Outputs: Histogram of the score for each images given a set of models Automatically made plots for the distributions of the scores Satistics (average, standard deviation, min, max) for the score of a set of models given a class average.
- python 2_modeling_allEM_except11_19.py -r repeats -out outputdir -rmf starting_rmf -rmf_n rmf_frame -em2d class_average -weight em2d_weight
The script will generate independent and uncorrelated trajectories, refined from the best-scoring configurations after the EM filter. All data and information available for the system, including chemical cross-linking data, excluded volume, atomic structures, and 21 good EM 2D class averages (except classes 11 and 19) are used.
Author(s): Seung Joong Kim, Ilan E. Chemmama, Riccardo Pellarin
Date: October 6th, 2016
License: CC BY-SA 4.0 This work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
Last known good IMP version:
Testable: Yes.
Parallelizeable: Yes
Publications:
- J. Fernandez-Martinez*, S.J. Kim*, Y. Shi*, P. Upla*, R. Pellarin*, M. Gagnon, I.E. Chemmama, J. Wang, I. Nudelman, W. Zhang, R. Williams, W.J. Rice, D.L. Stokes, D. Zenklusen, B.T. Chait, A. Sali, M.P. Rout, Structure and Function of the Nuclear Pore Complex Cytoplasmic mRNA Export Platform, Cell, 2016, 167(5), 10.1016/j.cell.2016.10.028.